
一村淞灵专注于早中期投资,致力于构建一个强大的AI生态朋友圈。AI竞赛中,无论是模型或数据的优化,还是算力的提升,都离不开坚实的基础设施。本篇文章作为《航海日志》系列的延续,将深入探讨AI基础设施产业链中的细分领域——芯片与模组,并针对AI集群的互联部分进行研究探索。

在大模型训练过程中,有一种设想是当模型参数结构复杂到一定程度之后,模型突然展现出一些新的、未被明确编程的能力或行为,具有一定的不可预测性和非线性特征,我们称之为“智能涌现”。

图片来源:GPT4o生成
从Transfomer算法的横空出世到对规模定律(Scaling Law)的执念追寻,从模型到算力,从OpenAI到NVIDIA再到DeepSeek,人类开始了一种前所未有的内卷方式去探索这种智能涌现的可能。
2024年12月,DeepSeek V3正式发布,通过创新的稀疏混合专家架构(Sparse MoE)实现了参数规模与训练成本的突破性平衡。新年伊始,DeepSeek R1的推出则吹响了AI技术平权的号角,开辟了AI在有限资源下技术追赶的新路径,AI开始走进千家万户。正如杰文斯悖论(Jevons Paradox)中提到的:“技术进步使得资源利用效率提高时,反而可能导致资源的总体消耗增加,而不是减少”。
这轮AI革命的一大特点是算力基础设施的升维竞赛,当下从模型到数据再到算力的升维周期又一次开启了,当行业目光聚焦于模型算法创新时,支撑智能进化的底层硬件网络正在酝酿更具确定性的增长机遇。其中端侧智能对于模型、算力的升维标准与迫切需求,催生了通往AGI时代又一波的非线性增长机会。
本专题将围绕AI基础设施产业链,重点关注芯片和模组环节,分别将计算、存储和互联三个细分领域作为研究主旨,本文是该系列的第一篇研究报告,将着重对AI集群的互联部分进行研究探索。
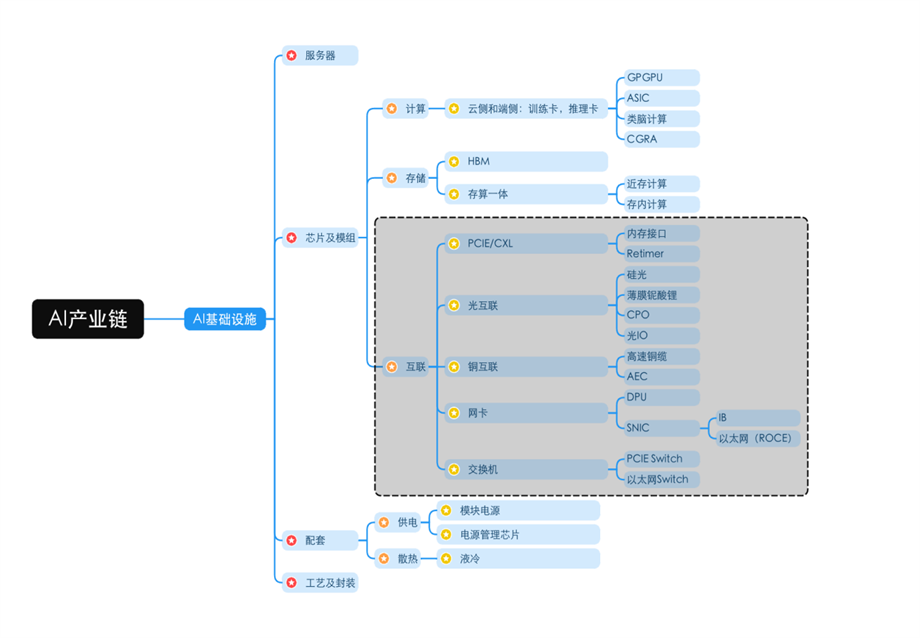
一村淞灵团队AI基础设施投资图谱
集群互联:重塑千亿参数时代的底层秩序
规模化的集群互联对智能涌现的触发具有结构性催化作用,其意义或许不只是单纯的算力堆砌,而是通过网络拓扑革命与信息动力学重构,为智能的质变创造必要条件。因此极致的性能追求是AI数据中心的核心目标,由此产生两条齐头并进的技术路径:Scale-Up(纵向提升服务器内算力卡性能)和Scale-Out(横向堆叠服务器的数量)。摩尔定律的放缓带来的芯片工艺的革新难度加大,单个服务器算力的提升缓慢而艰难,Scale-Out集群化成为AI数据中心算力问题的重要解决路径,由此造就了千卡,万卡集群的数据中心。

xAI Colossus数据中心计算大厅
图片来源:企业IT观察
大模型训练是基于并行计算范式,一个训练任务是计算—通信—计算这种周期性迭代的过程,所有GPU在一轮计算迭代后都必须同步参数和梯度才能进行下一轮的计算。这种情况下,集群中任何一处有网络拥塞或者故障都会影响整体训练的性能,具有很强的木桶短板效应,追求稳定的高性能网络互联正成为AI集群的最核心诉求。因此,随着AI集群化趋势越来越明显,AI基础设施建设逐步进入2.0时代,数据中心对于网络端的投入比例也在逐渐增加。
我国目前在AI基础设施尤其是芯片领域的关注还主要集中在算力的国产替代阶段,随着该领域技术和产品的逐步完善,AI网络端芯片将成为下一个亟需突破的环节。
AI服务器集群拓扑结构
在AI算力集群中,叶脊架构(Leaf-Spine)及其变体(如胖树Fat-Tree)正成为主流拓扑选择,其核心驱动力源于GPU并行计算引发的东西向流量爆炸式增长。相较于传统三层架构的南北向流量主导模式,叶脊架构通过多路径、无阻塞互联与分布式路由策略,将数据流动态分散至多条链路,完美适配AI训练中高频的跨节点通信需求(如参数同步、梯度聚合)。
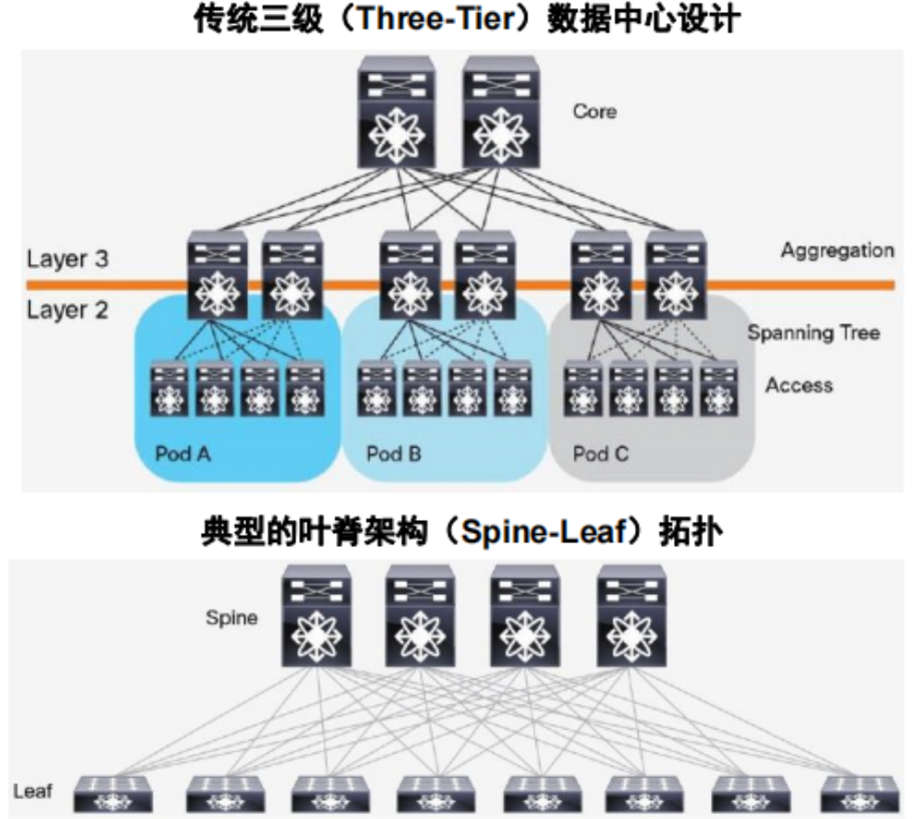
图片来源:Cisco,国信证券
这种设计在保障集群横向扩展(Scale-Out)灵活性的同时,具有以下重要意义:
算力集群的线性增长。每新增一个GPU节点,仅需按需扩展叶/脊层交换机,无需重构全网拓扑,集群规模可从百卡无缝扩展至万卡级。
通信延迟的保障。通过自适应负载均衡算法,叶脊架构将跨节点通信延迟方差控制在10%以内,为万亿参数模型的同步训练提供稳定的延迟保障。
故障隔离与弹性冗余。单链路或单节点故障仅影响局部通信路径,结合智能重路由协议,集群可用性可达99.999%。
集群的主要互联形态
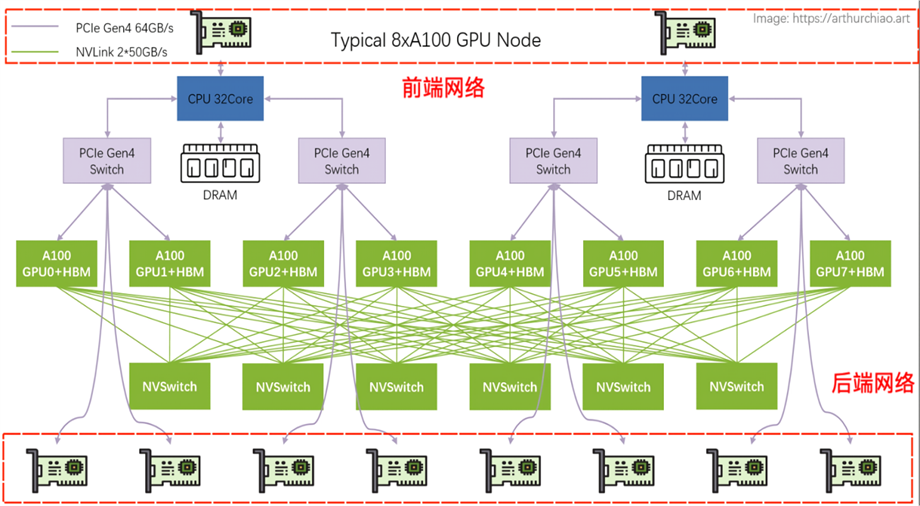
目前AI集群的网络通信路径设计需在纵向性能(Scale-Up) 与 横向扩展(Scale-Out)间取得平衡,同时兼顾前端服务与存储访问的实时性需求。一个典型的NVIDIA 8卡A100的主机硬件拓扑架构如下图所示:
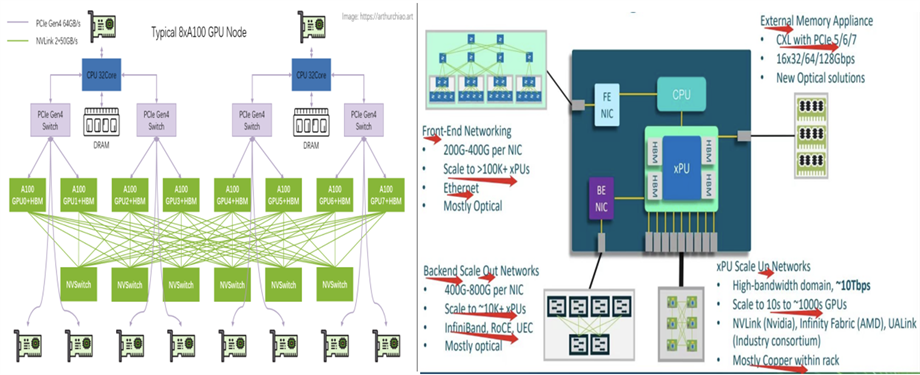
图片来源:https://arthurchiao.art
NVIDIA典型8卡A100主机硬件拓扑
因此,AI集群的互联网络主要由以下三种形态构成:
(1)前端网络负责连接传统数据中心网络、存储系统等,主要通过智能网卡进行数据收发,以光作为传输介质,前端网络对于网卡性能的需求要低于后端网络,目前100G和200G智能网卡基本上能满足要求。
(2)在Scale-Up网络中,算力卡之间通过NVIDIA NVLink和NVSwitch进行互联,这种情况下,NVLink4.0双向速率可以达到600GB/s,或者通过PCIe 5.0协议以及Gen5 Switch进行互联,双向速率可以达到128GB/s,连接方式以铜互联为主。目前Scale-Up网络采用的主要互联协议包括:NVLink、PCIe和CXL(Compute Express Link)。NVLink4.0与PCIe5.0 对比仍然有着几倍以上的性能优势,一方面是因为NVIDIA的方案中每个GPU上都包含了不止一条 NVLink,并由NVSwitch提供了GPU的ALL-to-ALL连接,因此在GPU计算领域,NVLink对比PCIe的优势是巨大的,而PICe最大的优势在于其通用性以及开放性的生态。CXL则是一项基于PCIe物理层技术的新兴协议,目前尚未大范围普及。三种协议的对比如下:
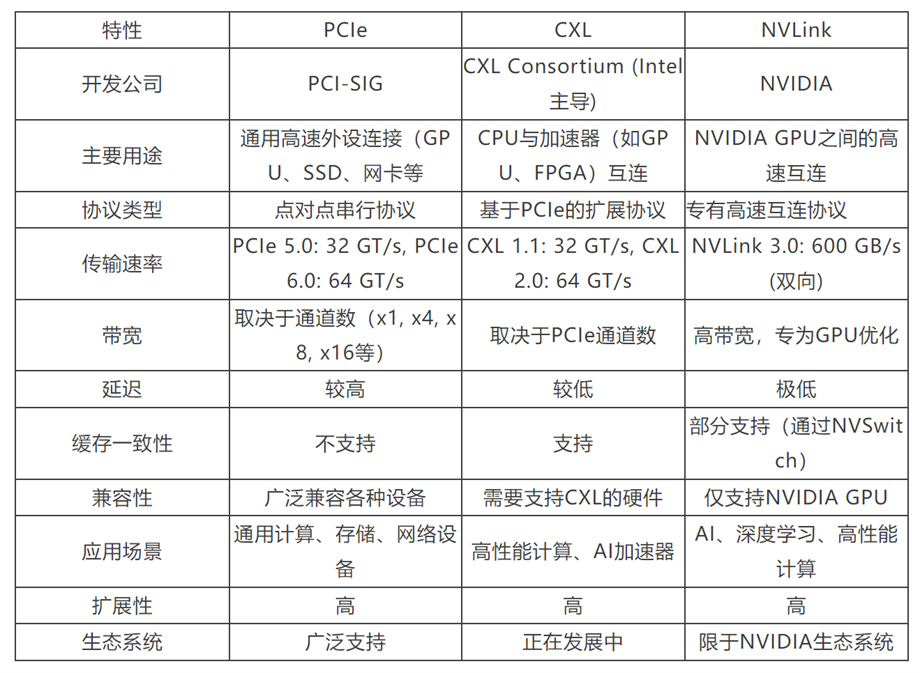
表格由一村淞灵团队重新整理
(3)Scale-Out网络通过智能网卡+光互联+高性能协议的三重赋能,实现算力网络的横向拓展。InfiniBand、RoCE、UEC分别代表了封闭极致、生态兼容与开源灵活的不同路径。目前主流的Scale-Out网络对于智能网卡的带宽要求在400G以上,并且主要通过光传输的方式进行组网。
集群互联中的重要技术
智能协同中枢—PCIe Switch
作为AI集群的重要接口协议,由于PCIe是串行接口,所以一个PCIe接口只能接一个PCIe设备,要想多接几个PCIe设备就需要用到PCIe Switch。PCIe Switch主要作用是在让节点的PCIe设备,包括GPU,CPU,内存以及网卡等设备通过PCIe协议进行更加高效的互联互通。
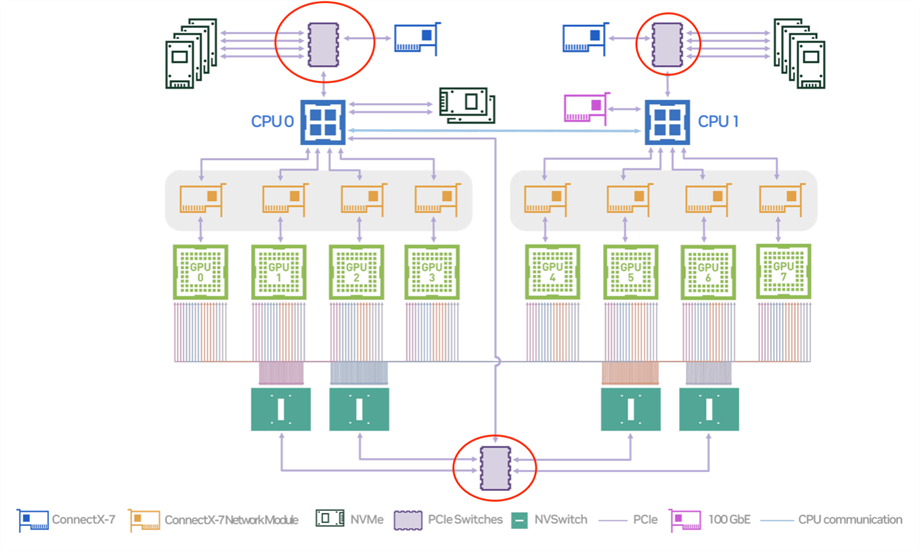
图片来源:NVIDIA官网
目前 PCIe Switch不仅已经被广泛应用在了传统存储系统中,而且在AI服务器平台也逐渐普及,用于提高数据传输的速度。以NVIDIA的DGX服务器为例,其需要配备2颗144通道的PCIe Gen5 Switch芯片,用来连接CPU,GPU以及CX7网卡,每颗PCIe Gen5 Switch芯片价格是400—450美元之间,PCIe Gen4 Switch芯片价格大概在200—300美元之间,且长期处于供不应求的状态。
目前全球PCle Switch三大供应商,博通、微芯和祥硕科技共占有全球约58%的份额。根据QYResearch的统计及预测,2028年全球 PCIe Switch芯片规模会达到18亿美元,而我国在AI高端领域的市场占有率近乎为0,国产替代空间巨大。
信号的再生引擎—Retimer
无论是NVlink还是基于PCIe的其他传输协议,传输速率的提升是必然的趋势。由于目前节点内互联主要的传输介质是铜线,而随着传输速率的提升,整个链路的插损也大大增加,对集群的通信效率影响巨大,因此解决链路的插损问题尤为重要。
Retimer芯片的核心作用是恢复信号质量和同步时序,尤其是在长距离或高频率的数据传输中,它通过在传输链路上插入,帮助消除由于信号衰减、噪声和抖动造成的问题,确保信号在到达接收端时依然清晰、可靠。Retimer芯片的关键在于:(1)是否有能力准确接收到存在插损的信号;(2)是否能够将插损信号恢复后再传输出去。
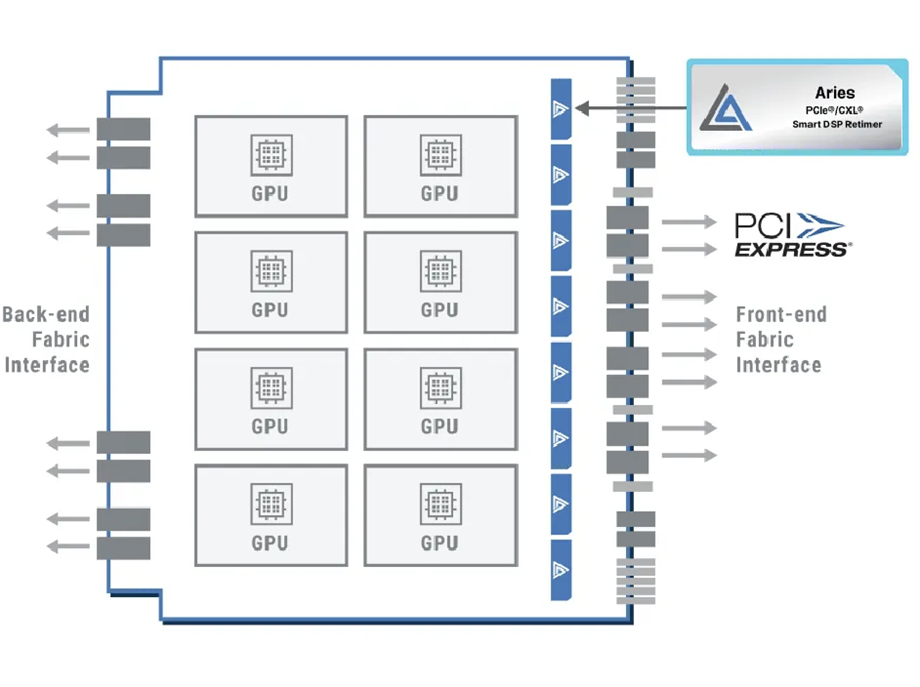
图片来源:Astera Labs官网
Astera Labs的Retimer芯片
AI服务器时代,PCIe Retimer芯片的需求量在不断增加。在NVIDIA的DGX服务器中,一张通用基板上部署有8颗GPU芯片,上面的CPU板上放置了2颗CPU芯片。目前,8颗GPU会配置8颗PCIe Gen5的Retimer芯片,上方CPU节点也会配备8颗对应的Retimer芯片,即一台主流的DGX AI服务器大概需要配备16颗Retimer芯片,后续Scale-Up组网的进一步迭代,对于PCIe Retimer芯片的需求也会进一步增加。此外,有源铜缆从ACC向AEC过渡,也会增加Retimer芯片的需求(AEC需要利用Retimer芯片对电信号进行重新定时和重新驱动)。总体而言,随着传输速率向更高速发展(如PCIe 6.0、800G/1.6T以太网等),Retimer芯片将成为不可或缺的组件,以应对更高的技术挑战。
异构算力粘合剂—CXL
AI数据中心面临的一个核心挑战是GPU性能与内存可扩展性之间的差距正在不断扩大,如下图所示:
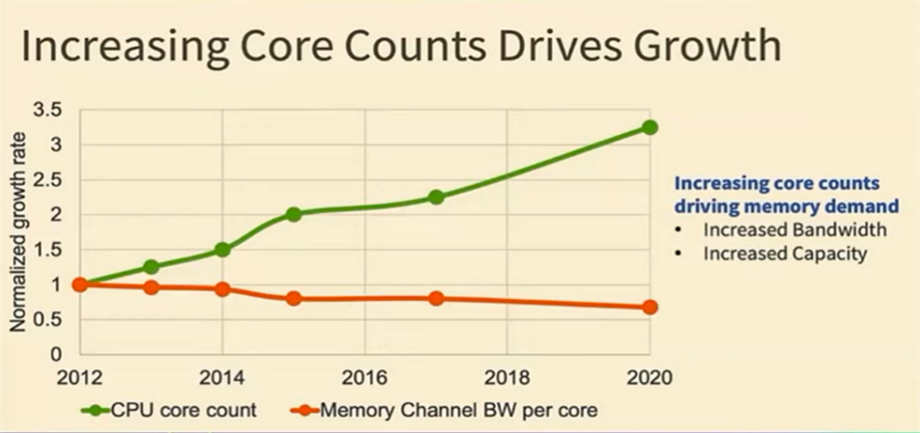
图片来源:OCP(开放计算项目)技术研讨会
这一问题在大模型训练任务中尤为突出,因为这类任务对内存的访问频率和容量提出了更高的要求。随着模型规模的持续增长,GPU的计算能力迅速提升,但内存带宽和容量却未能同步扩展,导致性能瓶颈日益显著。这种失衡不仅限制了训练效率,还可能增加硬件成本和能源消耗,进一步加剧了数据中心的运营压力。
CXL协议就像是计算机世界里的“万国语”一样,通过跨机柜的资源解耦、池化和共享,让不同的硬件设备可以高效地进行通信和协作,通过内存池化、设备共享和低延迟互连,解决数据中心面临的“内存墙”和异构计算资源调度难题。当前,CXL 3.0协议已支持多层级拓扑和缓存一致性,英特尔、AMD等芯片巨头已将其集成至新一代处理器,三星、美光等厂商也推出CXL内存扩展方案,技术生态初具规模。而制约CXL发展的主要因素还是生态系统成熟度不足 尽管英特尔、AMD等巨头已布局CXL,但全产业链支持仍不均衡。内存厂商需开发兼容CXL的扩展模块,软件生态尚处于早期阶段,应用场景的适配和优化仍需时间积累。
隐形算力杠杆—智能网卡(SNIC)
智能网卡的应用场景主要是针对Scale-Out网络的横向扩展,目的是为了实现跨集群的数据流动,采用的协议包括InfiniBand或RoCE ,应用在前端和后端两个网络中。
前端网络主要聚焦于南北向流量,负责AI集群与云数据中心存储资源(如分布式文件系统、对象存储)的对接。AI服务器内部的CPU负责传输数据,同时每个CPU都配备自己的智能网卡,一般单个节点会部署2张100-200G以太网存储网卡(如NVIDIA ConnectX-6),通过光互联进行数据传输。
后端网络主要聚焦于东西向流量,实现节点内网卡与节点外网卡的通信,网络协议一般是InfiniBand或RoCE,通过光互联进行数据传输,对于单机8卡服务器而言,一般会配备4张左右的智能网卡,以确保网络性能不会成为瓶颈,DGX100会配备8张智能网卡,带宽要求至少在200Gb/s以上。
图片来源:https://arthurchiao.art
智能网卡的一项核心技术是RDMA (Remote Direct Memory Access),是一种高性能网络通信技术,能显著提升数据传输效率,通过RDMA远程直接地址访问,本端GPU/AI芯片可以直接访问远端节点GPU/AI芯片的内存,如下图所示。
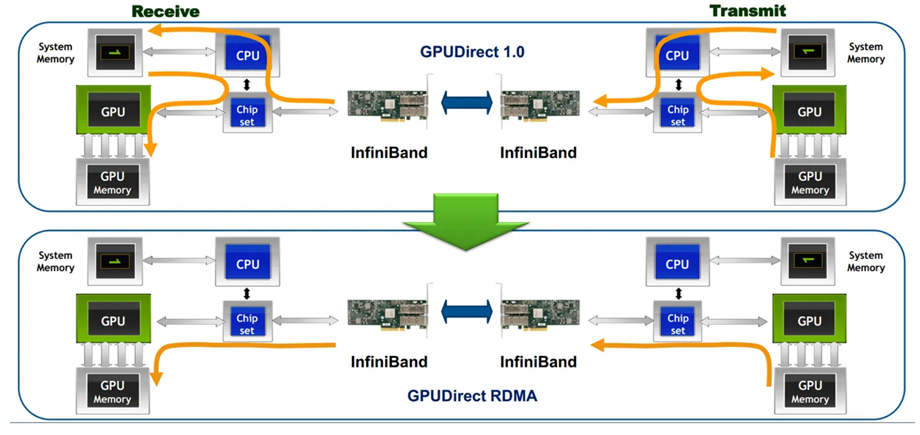
图片来源:https://developer.aliyun.com/article/603617
目前,AI智能网卡主要由NVIDIA和博通所垄断,其供应给数据中心的网卡主流传输速度已经达到200G/400G的水平,支持800Gb/s的以太网网卡也已开始出货,国内目前智能网卡能够达到量产要求的还集中在100G—200G区间,且主要是支持前端网络。
根据IDC和Dell‘Oro Group预测,2027年国内服务器出货量预计达到560万台,其中AI服务器大约为65万台。结合这个数据,根据AI服务器的标准配置方案,每台AI服务器配置4-10张网卡,预计国内AI网卡的市场规模在100—150亿人民币左右,是除了GPU计算芯片外,AI服务器中价值量第二高的芯片类别。
集群互联中的主要传输介质
光传输
目前数据中心不论是InfiniBand以及以太网组网,机架之间互联存在光纤和铜互联两种方式,其中,机架内短距离优先使用铜缆,而在中远距离则采用光纤+光模块方案,总体而言约超过75%的连接方式以光为主,主要得益于其能支撑更高的通信速率以及更远的传输距离。
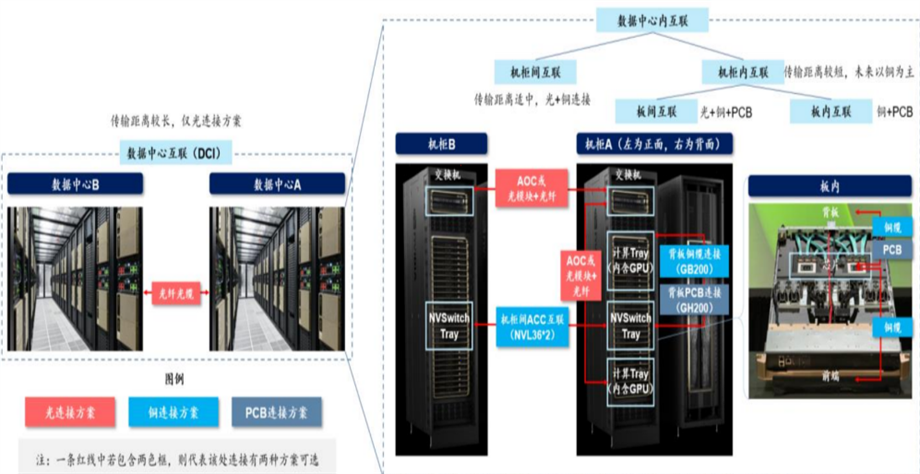
资料来源:NVIDIA官网,SemiAnalysis,华泰研究
目前主流的AI服务器组网按照叶脊架构,如果Scale-Up和Scale-Out的集群组网模式继续拓展,则高速光模块的需求也将进一步增加。以NVIDIA为例,早期NVIDIA H100 AI服务器组网,GPU芯片和800G光模块的比例仅仅约为1:2.5,而通过NVIDIA GH200服务器进行组网,GPU芯片与800G光模块的比例会将达到1:9以上。

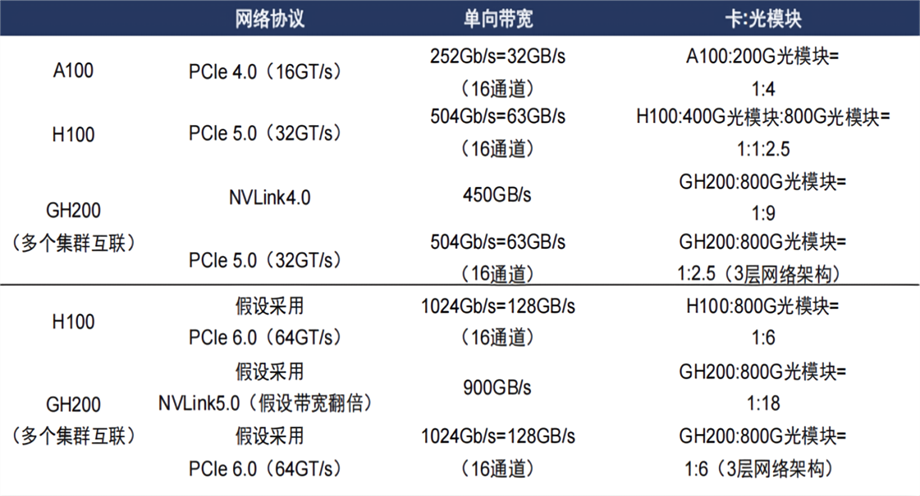
资料来源:华泰研究
硅光芯片硅光在高速、高集成、低功耗三方面具有理论上的巨大优势。在高集成度层面,工艺一旦成熟,成本能够快速下降,并且在寸土寸金的AI服务器中占据的空间资源很少,可以有效适配CPO技术;另一方面是以InP为代表的传统光芯片在100G速率以后难以进一步进行演化(功耗、尺寸、成本之间非常难平衡),而硅光芯片能够从容应对高速率与多通道挑战,得益于其在硅基平台上实现的大规模集成,使得成本不会随通道数和传输速率的提升而显著增加,因此在AI时代具备天然竞争优势。

资料来源:中科院微电子研究所,徐芳露等《硅光芯片-后摩尔时代的高速信息引擎》
目前硅光的100G方案已经很成功,但是总体市占率并不高,在800G以下的硅光还不足以和传统光芯片拉开差距,再加上硅光的技术和工艺也持续要改善,成本并未显示出优势,所以当前800G以下硅光的市场份额大概在20%左右。但是1.6T(2025年预计有400万的需求量)以上速率则会大规模取代传统方案,有一个较大的增长空间。其后续的一个重要的增长逻辑是:硅光方案可以在性能不断提升的情况下,成本不会有太大的增长,参照摩尔定律的发展轨迹,将来可以实现更高速率,但是成本又可控。
电光调制器是高速光模块的核心器件,其电光调制速率决定了光模块的数据传输速率,目前主要可分为:硅光调制器、磷化铟、铌酸锂调制器三类。
在1.6T层面,目前硅光有两种方案可以实现,第一种是单100G用16个通道去做,第二种是200G用8个通道去做,这也意味着单通道的速率从原来单波100G提到200G,但该方案难度大。因为硅本身材料有限制,导致高频响应带宽不是特别好,导致很难突破单波200G,这也是硅光路线继续往更高速率上做的一个主要问题。
薄膜铌酸锂可实现超快电光效应和高集成度光波导,具有大带宽、低功耗、低损耗、小尺寸等优异特性,并可实现大尺寸晶圆规模制造,是非常理想的电光调制器材料,其调制速率的极限可以达到400G,因此在更高速率的需求下有较大的应用价值。
目前限制薄膜铌酸锂调制器应用的一直重要原因是其加工工艺难度较高(铌酸锂薄膜相对较硬,组成特殊,难以刻蚀),需要通过重资产的IDM模式重新打通各个制造环节,并且铌酸锂材料本身的成本较高,导致目前的商业化进度相对较低,目前主要的应用集中在军工等领域。现在已经有一些大厂已经开始坚定的推行薄膜铌酸锂方案路线了,例如Arista等公司,一旦数据中心对于通讯速率的需求达到1.6T以上,我们相信薄膜铌酸锂的落地进程一定会加快。
总体而言,我们认为在800G的DR8层面,传统InP方案下的EML还会是主流并且不会被硅光方案取代。但在800G的FR4以及1.6T的DR8方案以及再往上的速率,EML方案的市场空间将会不断被压缩。未来的高速光模块市场的很有可能是硅光和薄膜铌酸锂的天下。
过往芯片之间的铜互连技术长期依赖TSV(硅通孔)等先进封装工艺实现高密度布线,但随着AI 2.0时代对数据中心提出更高要求:数据吞吐量呈指数级增长、单芯片算力需求激增且功耗严格受限、异构计算架构推动计算资源解耦,这种情况下传统电互连方式逐渐暴露出瓶颈,需要高性能的光IO来应对这些问题。
在IEDM 2024大会上,NVIDIA介绍了对未来人工智能加速器的设计,其计划引入硅光子技术,作为IO器件。需要12个硅光子IO器件来实现芯片内和芯片间的连接,每个GPU模块有三个连接,每层有四个GPU模块,每个GPU模块与六个DRAM内存模块垂直连接。
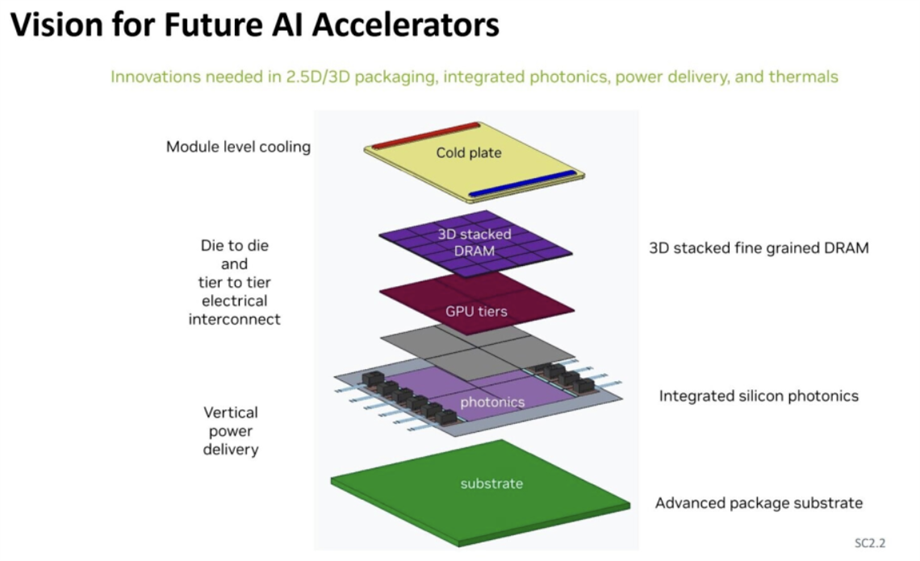
资料来源:IEDM 2024
Ayar Labs的研究数据显示,GPU集群规模扩大会导致显著的规模不经济效应:单GPU芯片的运算效率约为80%,但当集群规模增至64颗GPU时效率骤降至50%,而256颗GPU的协同效率甚至可能跌至30%。这种效率衰减主要源于传统电互连的带宽瓶颈与信号延迟,尤其在数据密集型AI训练场景中,跨节点通信开销会吞噬大量算力资源。光IO方案相比传统互连可实现约5-10倍的更高带宽、4-8倍的能效,并将延迟降低至1/10。这样一来,集群规模的拓展在经济性和效率上都将有很大的提升。
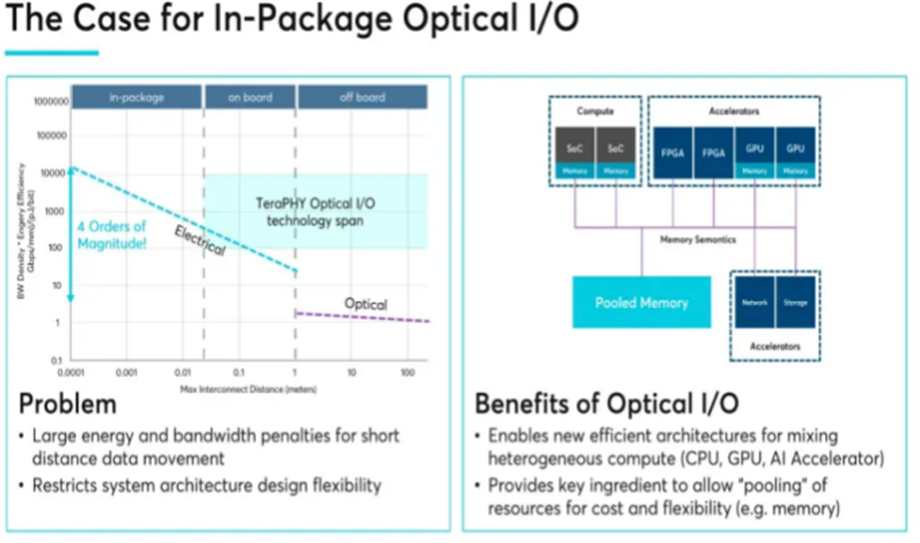
资料来源:Ayar Labs
正是由于光IO对于AI数据中心集群能效影响巨大,目前NVIDIA,英特尔,三星以及Marvell等巨头都在积极推进光IO的产业化进程,我国也有一些创业公司开始进行技术和商业化探索,但我们预计光IO的商业化速度不会一蹴而就,还需要解决工艺、成本以及供应链成熟度等问题,后续落地进度预计会在2026年之后。
铜传输
在2024年NVIDIA GTC大会上,其推出的GB200超级芯片与NVL72机柜引发了业界对高速铜互联技术的广泛关注。不同于传统光互联方案,此次NVIDIA通过多节点高速铜缆互联构建了“类超级GPU”架构,将多个GPU芯片通过高密度铜缆互联形成统一的计算单元,显著提升了集群内节点间的带宽与能效比。当前,高速铜连接技术在AI数据中心中的应用主要集中在以下三个场景:
背板级互联:通过高密度铜缆实现同一机柜内多GPU的互联,带宽可达500GB/s以上,满足千卡级训练的实时同步需求。
外部I/O扩展:借助铜缆的灵活性与低成本优势,为GPU集群提供高速访问外部存储与网络的接口,平衡了性能与部署复杂度。
近芯片级集成:在芯片封装层面,铜缆直接连接GPU与协处理器,实现微秒级延迟的近场通信,支撑存算一体架构的实时数据处理。
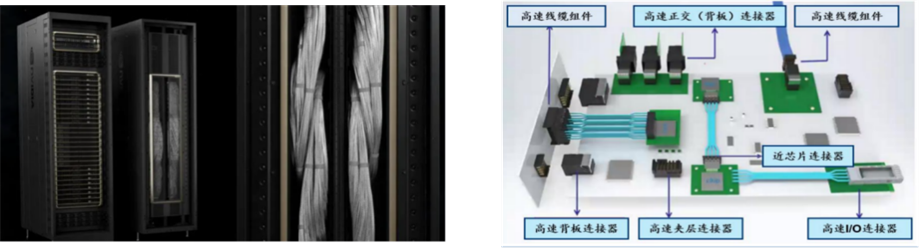
资料来源:华泰研究
在AI数据中心场景中,铜互联技术虽凭借低成本与易部署特性广泛应用于短距互联,但其固有物理限制仍是核心挑战:传输速率与传输距离呈负相关(速率越高,信号衰减越严重),典型瓶颈表现为100G PAM4铜缆有效传输距离不超过15米。这一特性决定了铜互联主要适配短距场景。目前铜互连有以下三种方案:
DAC(Direct Attach Copper),也称为直连电缆,由镀银铜导线和泡沫绝缘芯线制成的高速电缆组成,其不可更换的一体化设计虽牺牲了灵活性,却换取了极致的信号完整性,使其在AI数据中心短距互联中应用广泛。
ACC(Active Copper Cable),有源铜线是一种有源铜线,它利用Redriver芯片架构,并采用CTLE均衡来调整Rx端的增益。本质上,它的作用是作为一根有源电缆放大模拟信号。
AEC(Active Electrical Cable),AEC有源电缆代表了有源铜线电缆的一种更具创新性的方法。它利用了Retimer芯片架构,该架构不仅放大和均衡Tx和Rx端子,而且重塑Rx端子处的信号。AEC retimer目前主要是8通道50G的方案。
AI训练及推理对网络速率的需求不断提高,从400G向800G过渡的过程,DAC的传输距离越来越小,已经不能满足需求,AEC在性能方面的优势便逐渐崭露头角(可以实现7米以内的布线),性能比ACC要更好,随着224G PAM6与Chiplet技术的成熟,AEC有望成为下一代算力集群的“血管级”互联技术。
结语
互联技术是AI算力革命的“隐形引擎”,其本质是通过物理层、协议层与调度层的协同进化,将摩尔定律的单点算力增长升维至全局算力共振,从这个逻辑上讲,在通往AGI的道路上,谁掌握了互联技术的制高点,谁就拥有了一把打开智能时代算力开关的钥匙。
智能涌现的探索是一条漫长之路,在transformer体系可预见的将来,模型优化和算力堆叠还将继续重复往返的内卷下去,但我们也会时刻关注可能颠覆transformer的全新架构体系,因此对于AI基础设施的兼容性与拓展性也提出了新的课题与挑战,淞灵团队将继续围绕AI产业链展开一系列研究,深刻关注这其中发生那每一次技术进步和变革。

来源:istock
References:
1、https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-to-dgxh100.html#hardware-overview
2、https://arthurchiao.art
3、https://www.asteralabs.com
4、https://blocksandfiles.com/2025/01/13/panmnesia-gpu-cxl-memory-expansion/.
5、Dagley, Rick. "Gartner 2024 IT IOCS Highlights: Equipping IT I&O Leaders for an AI Future." ITPro Today, December 30, 2024
6、Raguraman Sundaram, Celestica. "Ethernet in the Age of AI: Adapting to New Networking Challenges." YouTube, November 19, 2024.
7、公众号:Andy730
8、公众号:信息平权
关于一村淞灵
一村淞灵是一村资本位于深圳的全资子公司,专注AI早中期投资,打造淞灵AI生态朋友圈。
关于深圳一村淞灵私募创业投资基金管理有限公司(简称“一村淞灵”或“公司”)一村淞灵成立于2013年,是一家位于深圳的长期聚焦人工智能、数字经济的私募股权投资管理机构。自成立以来,以其深植产业的投资逻辑、成熟专业的投资能力,公司先后发起并受托管理了国家科技部、国家发改委、深圳市引导基金、青岛市经信委、深圳市天使引导基金、前海引导基金等多支政府参股基金,在管资产规模达20亿元。
通过践行产融结合的投资策略和管理模式,经典案例包括:生命科学智造企业华大智造、医药数字化平台“药师帮”、光电半导体企业“纵慧芯光”、全球领先的AI视觉服务商“视比特机器人”、全栈式3D视觉解决方案提供商“光鉴科技”、致力于颠覆式创新的AI芯片设计商“墨芯科技”、专注于云计算和数据中心数据处理器芯片(DPU)和解决方案的领先半导体公司“云豹智能”。
提示:私募基金仅面向与基金风险等级匹配的合格投资者推介或募集。投资有风险,投资者应理性作出投资决策、自行承担投资风险;本公司不作保本保收益或投资无风险的承诺。私募基金产品风险等级评分表详见网站媒体中心页面。
