
AI Startup Gyrfalcon spins plethora of chips for machine learning
AI Startup Gyrfalcon spins plethora of chips for machine learning
By Tiernan Ray | | Topic: Artificial Intelligence
Thirty years ago, a PhD student named Lin Yang at the University of California at Berkeley had an idea for a special kind of chip that would speed up computations for artificial intelligence.
Think of it as a three-decade head start.
Some of those insights are now reality, as Yang's startup company, Gyrfalcon Technology, of which he is chief scientist, moves forward with an ambitious string of different chip offerings for AI, hoping to best an increasingly crowded field of chip contenders.
Gyrfalcon, based in Milpitas, on the edge of Silicon Valley, and founded in early 2017, is realizing Yang's insight from thirty years ago: a matrix of identical circuits performing matrix multiplications in parallel, thereby speeding up the fundamental operations of neural networks.
Also: AI startup Flex Logix touts vastly higher performance than Nvidia
"We are the only ones to get this far with matrix multiply as the fundamental compute element," says Gyrfalcon president Frank Lin, who sat down to talk with ZDNet.
Lin is well aware throngs of startups are boasting of novel semiconductor designs for AI, such as those recently profiled by ZDNet, including Cornami, Flex Logix and Efinix.
"The other chip makers, some of them are thinking about new architectures for matrix or tensor," says Lin, but with Gyrfalcon having provided first silicon to its clients in January, "for the real chip, we are, I think, the only one with real silicon on the table."
Some substantial customers have bet Gyrfalcon will deliver the goods they need, including Samsung Electronics, LG Electronics, and Fujitsu.
"We started with just seven people," adds Marc Naddell, head of marketing for Gyrfalcon. "Imagine just a small squad of people focused on taping out a chip within eight months of starting out." Gyrfalcon is the only partner for Samsung for an AI chip, both Naddell and Lin emphasize.
"We really had a successful first chip, that is why such a small company with a short history won the big logos" like Samsung, he observes.
Also: AI Startup Cornami reveals details of neural net chip
The key for the company's parts is that it boasts of energy efficiency that bests the performance of conventional CPUs from Intel and GPUs from Nvidia. "We are David going up against Goliath," says Lin.
The "Lightspeeur," as the company's parts are branded, began with the "2801" chip, unveiled in January of this year at the Consumer Electronics Show, a part used for "inference," the part of machine learning when the neural net uses what it has learned during the training phase to deliver answers to new problems. That part was aimed at "edge" devices such as smartphones, smart speakers, or laptops.
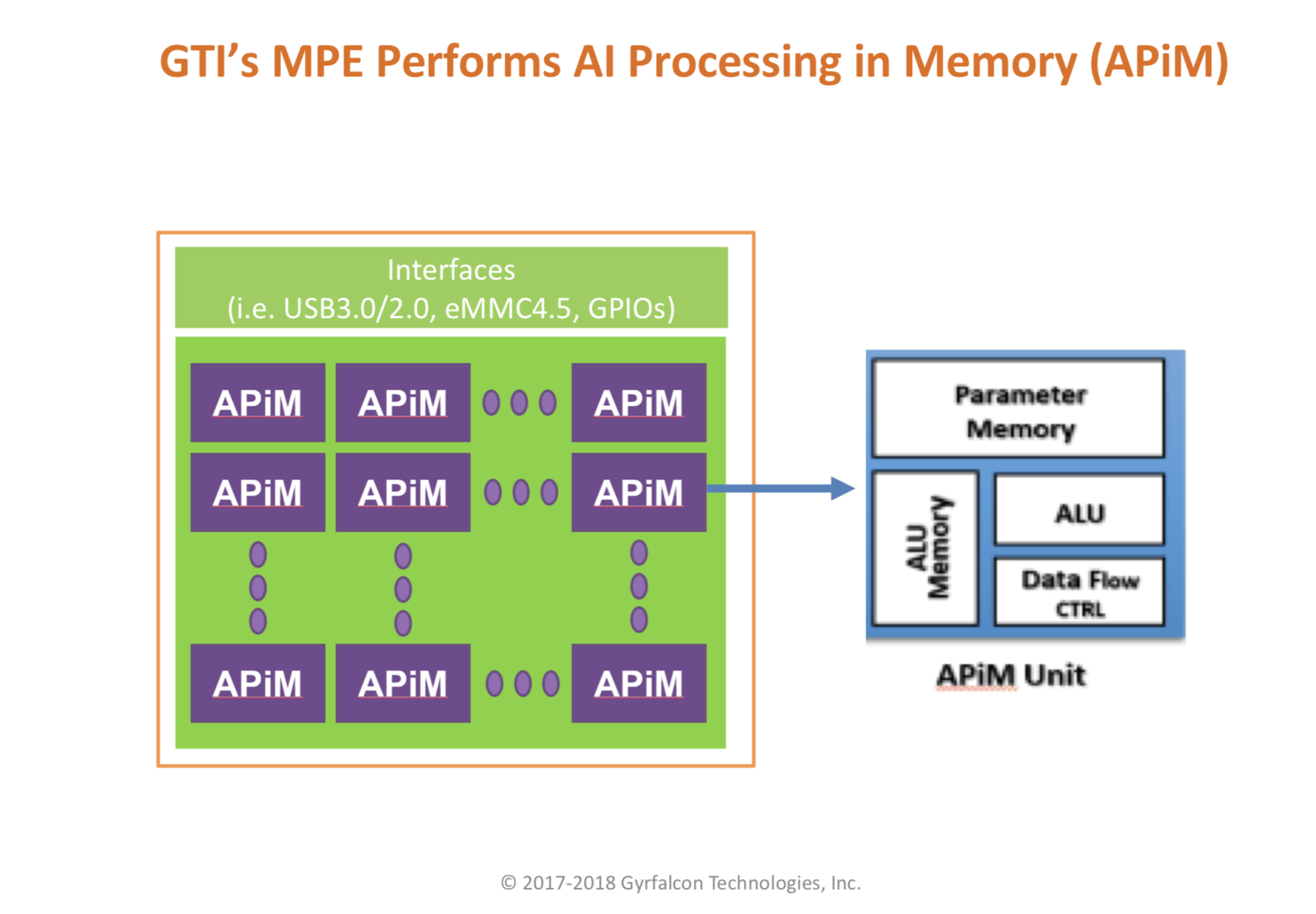 Gyrfalcon argues that by surrounding each identical computing unit with memory, an approach it calls "AI Processing in Memory," or APiM, use of external memory can be greatly reduced, thereby lowering the power budget of AI chips drastically.
Gyrfalcon argues that by surrounding each identical computing unit with memory, an approach it calls "AI Processing in Memory," or APiM, use of external memory can be greatly reduced, thereby lowering the power budget of AI chips drastically.
The 2801 offers the ability to compute 9.3 trillion operations per second in one watt of energy, where each operation is a multiply-accumulate step. Such "TOPS" measurements are a common expression of energy efficiency in AI chips these days.
It's "90% more power-efficient than Intel's Movidius part," says Lin, referring to the inference chip that Intel acquired with its purchase of the company of the same name.
The 2801 was followed last month by the "2803," which was designed to handle more heavy inference loads in cloud servers. It takes the performance and energy benefits further, offering 24 TOPS per watt of energy. Gyrfalcon proposes the 2803 can be used for not just inference but training as well, using an technique to optimize the network known as "Markov Chain Monte Carlo," in place of the more common stochastic gradient descent.
Also: Chip startup Efinix hopes to bootstrap AI efforts in IoT
Both 2801 and 2803 can be combined on circuit boards to operate in parallel as plug-in boards via PCIe.
Both parts have had embedded memory, on the order of 9 megabytes for the 2801. The memory, clustered with each computing element, allows the chip to do almost all the work of inference without having to go off-chip to DRAM. The company refers to this as "AI processing in memory," or "APiM."
"I can pre-load onto the chip just one time the network model and the weights and the activation units," says Lin, "and then not have to go outside; that saves a lot of energy, and that is why the performance is that high."
And this month, the company gave a bit of a peak at its next part, one focused on "Internet of Things" applications, which will not be formally announced until next month. The newest part, the 2802, brings another interesting aspect to the table: non-volatile memory.
The 2802 replaces the static RAM (SRAM) used in the 2801 and 2803 parts with "magnetic" RAM, or MRAM. Similar to NAND flash, MRAM doesn't loose its data when the power goes out. That means that a neural network could be pre-loaded by a customer, perhaps even at the factory, before the part ships.
Gyrfalcon's approach to fabricating MRAM on the same die as the multiplier-accumulator units, is among fifty patent applications the company has in process. A quick search of the U.S. Patent Office's application database, as well as the awarded patents, offers a nice reading list on the details of Gyrfalcon technology. (Berkeley was awarded a patent in 1992 on Yang's original chip design, with his supervisor, Leon Chua. Chua's extensive work in the field, incidentally, can be explored in a number of areas, including Chua's 1998 book, "Cnn: A Paradigm for Complexity.")
Also: Intel's AI chief sees opportunity for 'massive' share gains
Of course, the rub is software. Unlike the CPU and GPU, there is no readily available programming stack for Gyrfalcon's application-specific integrated circuit (ASIC).
A comparison by Gyrfalcon of its Lightspeeur chip approach to AI processing to that of Intel and Nvidia.
For that reason, the company has just released a developer SDK to build applications for the parts. The dev kit can be tested on two hardware accessories, the "PLAI Plug," a USB dongle, and the "PLAI WiFi," a stand-alone device that operates as a wireless acceleration gadget for mobile devices.
By following down the path Yang paved at Berkeley, Gyrfalcon has taken a step that might seem risky: it is basing its circuitry on convolutional neural networks, or CNNs. Yang's original thesis work focused on the convolution operation, although Yang at the time referred to such models as "cellular neural networks," a term Gyrfalcon still uses in its patent filings.
Although convolution neural networks have, of course, become some of the most important neural network designs in the last several years, this choice nonetheless makes the chips less readily applicable to other sorts of networks, such as "long short-term memory" networks.
Lin is not too concerned, however, about the theoretical limitations there.
"The CNN is the foundation for all the other AIs," says Lin. "We have done studies, and we found that the largest market share is still occupied by ResNet as well as MobileNet," forms of CNNs, he notes. Other startups are trying to be useful for all kinds of networks, observes Lin, "trying to cover all the existing or the coming neural networks, but I haven't seen a successful one cover everything as well and at the same time to be efficient."
Also: Google says 'exponential' growth of AI is changing nature of compute
If new networks emerge and claim substantial market share, "then we will put out another chip for that," he says.
An interesting thought is what happens as Gyrfalcon moves along the manufacturing curve and makes its circuits even more efficient. The initial parts have been made with Taiwan Semiconductor Manufacturing's 28-nanometer fabrication process, an older node compared to Intel and Nvidia's cutting edge parts.
"We are using 28-nanometer to defeat what others like Nvidia are doing at 7- or 12-nanometer," says Lin. "We are like rebels fighting tanks, but we win!"
Adds Naddell, "when we do move to 12- or 7-nanometer, what are these other companies doing to do?"
Another route for Gyrfalcon is to license its chip designs to other AI chip makers. Lin is not committed to doing that, but he sees plenty of potential. "Even another startup, like Graphcore, they are doing things very similar to us, but if they want to go big with it, they have to talk to us."
As in past media interviews, Gyrfalcon declined to say how much money the company has raised. Funding is an important question for chip startups, because it can take hundreds of millions of dollars, on average, for a company to go the distance from design, to first "tape-out" of circuits, to developing and supporting a customer base. Graphcore, at last count, had over $100 million in funding.
Gyrfalcon says that they have gotten "three rounds of funding from institutional and corporate investors in the U.S., Japan, Korea and China," adding that "at the current staff and expense rate, the company has the funds to operate for at least three years."
